
Software e sistemi informatici

 COMPUTER SCIENCE
COMPUTER SCIENCE
PoliMI: nei processori del futuro saranno utilizzati nano-circuiti magnetici che consentiranno lo sviluppo di nuovi sistemi di elaborazione dell’informazione più veloci, flessibili e compatti
14.10.2018
Testo dell’articolo
Questo risultato, descritto su Communications Physics nell’articolo Nanoscale spin-wave circuits based on engineered reconfigurable spin-textures, permetterà di sviluppare nuovi sistemi più veloci, flessibili e compatti di elaborazione dell’informazione nei futuri processori.
Il lavoro è stato coordinato dal Dipartimento di Fisica nell’ambito del progetto SWING (Patterning Spin-Wave reconfIgurable Nanodevices for loGics and computing) ed è frutto di una collaborazione con ricercatori del CUNY-ASRC (New York), CNR-IOM (Perugia) e Paul Scherrer Insititute (Villigen, Zurigo).
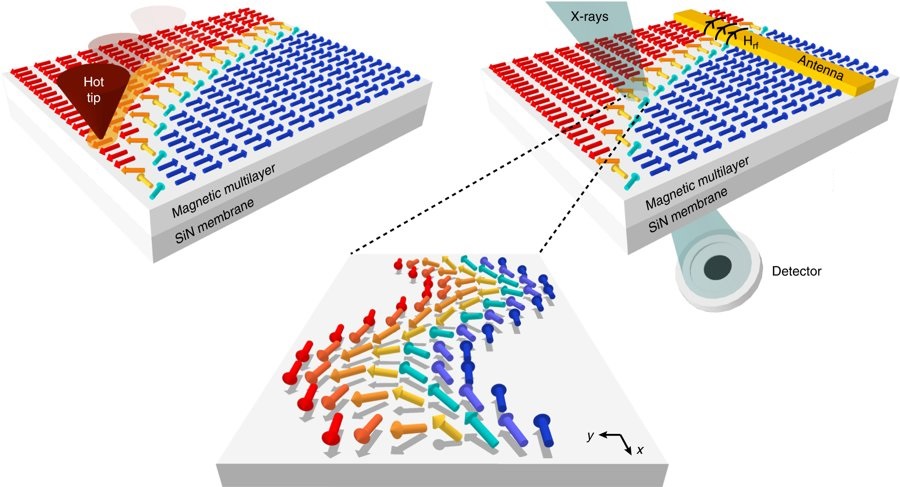
Image credit: Communication Physics (2018) DOI: 10.1038/s41467-018-05235-z
Le onde di spin sono l’analogo delle onde elettromagnetiche o acustiche nel campo del magnetismo. In un ferromagnete, ad esempio una comune calamita, gli spin, cioè i momenti magnetici dei singoli elettroni che compongono il materiale sono allineati in una direzione. Un materiale ferromagnetico è una sorta di mare di spin. Se in esso gettiamo l’equivalente magnetico di una pietra, si generano delle perturbazioni dell’orientazione degli spin che si propagano come le onde nel mare. Queste perturbazioni sono chiamate onde di spin.
Esse potranno essere utilizzate nei processori del futuro, per manipolare l’informazione in maniera veloce ed energeticamente efficiente, in modo analogo all’ottica integrata, con la differenza che le onde di spin possono avere lunghezze d’onda inferiori a quelle della luce visibile e quindi permettere una più spinta miniaturizzazione.
Fino ad ora però, realizzare circuiti logici in cui controllare le onde di spin con una precisione del nm (un miliardesimo di metro), era molto difficile. I ricercatori del Politecnico di Milano sono però riusciti a risolvere questo problema grazie alla tecnica tam-SPL con cui sono in grado di scrivere, cancellare e riscrivere a piacimento una configurazione di spin in un ferromagnete con la scansione di una “penna ultrasottile” (la punta di un microscopio a forza atomica). Questo ha permesso di realizzare per la prima volta guide d’onda nanometriche in cui le onde di spin posso viaggiare, curvare e interagire tra di loro, compiendo un significativo passo in avanti nello sviluppo di nuove piattaforme per i nostri computer o smartphone del futuro.
Testo redatto su fonte Politecnico di Milano del 10 ottobre 2018
Per approfondimenti: Nanoscale spin-wave circuits based on engineered reconfigurable spin-textures, DOI: 10.1038/s41467-018-05235-z – Communications Physics | 20.09.2018
Image credit: ARCHY13/SHUTTERSTOCK
© Copyright ADEPRON – Riproduzione riservata
 MACHINE LEARNING
MACHINE LEARNING
Costruire algoritmi capaci di estrarre informazioni dai dati di LHC per consentire ai sistemi informatici di fare predizioni senza che prima siano stati programmati per farlo
06.08.2018
Testo dell’articolo

Image credit: Claudia Marcelloni, Maximilien Brice/CERN (AUSSCHNITT)
Una tecnica di apprendimento automatico sta rivoluzionando il mondo con applicazioni innovative in molti settori, dai motori di ricerca al commercio online, dalla sicurezza informatica ai processi industriali, fino alla ricerca scientifica: il Machine Learning (ML). L’idea centrale è potente come le potenzialità che offre: costruire algoritmi capaci di estrarre informazioni e nozioni da un insieme di dati, consentendo a sistemi informatici che li utilizzano di fare predizioni senza che siano stati precedentemente programmati per farlo. In sintesi, algoritmi che girano sul computer e imparano dai dati, e che sono capaci di scovare informazioni nascoste nei dati stessi (ad esempio una nuova scoperta in fisica) con velocità ed efficienza maggiore di qualsiasi essere umano.
Le frontiere della ricerca nel ML oggi si muovono molto velocemente, e il potenziale di queste tecniche per la Fisica delle Alte Energie, in termini di approcci e strumenti software al servizio di nuove scoperte, è immenso, come dimostrato nell’articolo “Machine learning at the energy and intensity frontiers of particle physics” pubblicato su Nature.
La tecnica di ML non è una novità in sè, essendosi diffusa negli anni Novanta, ma il suo utilizzo è in fortissimo aumento proprio in questi ultimi anni in tutti gli ambiti della ricerca grazie alla crescita di capacità di calcolo a disposizione degli scienziati.
Questa tecnica si è dimostrata particolarmente utile nella Fisica delle Particelle, dove le moli di dati da analizzare sono impressionanti.
Il ML ha avuto un ruolo importante nella scoperta del bosone di Higgs, in cui l’impiego di queste tecniche in analisi dati ha portato a un aumento della sensitività sperimentale equivalente ad aver raccolto circa il 50% di dati in più nel Large Hadron Collider (LHC), l’acceleratore di particelle del CERN a Ginevra. Il ML ha permesso la scoperta in anticipo e con meno dati: a fronte di una scoperta possibile intorno al 2015-16, questa è avvenuta nel 2012, e ha valso il Nobel ai fisici teorici Peter Higgs e Francois Englert già nel 2013. Ma le applicazioni del ML non si fermano all’analisi dati: alcuni esperimenti di LHC usano il ML nei sistemi di selezione degli eventi (trigger) che provengono dalle collisioni di particelle, al ritmo di 50 TB/s (Terabytes al secondo), per selezionare con efficienza campioni molto accurati di eventi promettenti. Di grande interesse anche le applicazioni in sistemi di tracciamento e di identificazione di particelle, dove emergono soluzioni di Deep Learning, anche in esperimenti di Fisica Astroparticellare. Il ML svolge un ruolo importante anche nell’ottimizzazione dell’uso delle risorse di calcolo usate nei centri Grid in tutto il mondo, grazie a modelli predittivi e adattivi che rappresentano soluzioni di riferimento anche per altri settori, scientifici e industriali.
L’Istituto Nazionale di Fisica Nucleare (INFN) sta investendo molto sul potenziamento delle competenze e delle risorse per il calcolo scientifico nei settori del cloud computing e del ML. In particolare, la città di Bologna ospita dal 2003 il Tier-1, uno degli 11 centri di calcolo al mondo che gestisce l’elaborazione dati provenienti dall’LHC. Il Tier-1 è ospitato nella sede del CNAF, il Centro Nazionale dell’INFN per la ricerca e lo sviluppo nelle tecnologie informatiche e telematiche. In qualità di centro di calcolo principale dell’INFN, il CNAF si occupa della gestione e dello sviluppo dei principali servizi di trasferimento di informazioni e dati a supporto dell’INFN a livello nazionale.
L’INFN prevede di potenziare il CNAF trasferendolo nell’area del tecnopolo e integrandolo con quello del CINECA, andando a costituire così uno dei più grandi poli di calcolo europei.
Testo redatto su fonte INFN dell’1 agosto 2018
Per approfondimenti: Machine learning at the energy and intensity frontiers of particle physics, DOI: 10.1038/s41586-018-0361-2 – Nature | 01.08.2018
Image credit: gremlin/iStock/Getty
© Copyright ADEPRON – Riproduzione riservata
 BIOINFORMATICA
BIOINFORMATICA
Nell’ambito del progetto GeCo del POLIMI, una ricerca ha sviluppato GMQL, un avanzato sistema per interrogare dati genomici di grandi banche dati di Consorzi internazionali
07.07.2018
Testo dell’articolo
GeCo ha un obiettivo rivoluzionario: sviluppare e consolidare un nuovo approccio alla medicina integrando l’analisi di big data derivanti dal sequenziamento del genoma per trovare una risposta più precisa ed efficace a tante domande della biologia e della medicina, incluse la modalità di sviluppo dei tumori e la loro dipendenza da cause ambientali. GeCo vuole rivisitare la genomica computazionale tramite l’uso estensivo di banche dati pubbliche, ideando nuovi modelli, linguaggi e strumenti per la loro analisi e gestione, solidi dal punto di vista dei concetti utilizzati e capaci di operare in modo super-efficiente su sistemi cloud.
L’equipe del progetto GeCo ha sviluppato il sistema GMQL per interrogare dati genomici scaricati da grandi banche dati prodotte da Consorzi internazionali, un risultato che si colloca all’avanguardia mondiale della ricerca di settore. GMQL è un sistema aperto, utilizzabile pubblicamente, ed il Broad Institute (USA) lo ha reso disponibile ai suoi ricercatori.
Il Broad Institute è un centro di ricerca di eccellenza per la Genomica Computazionale e lo studio delle malattie, con particolare enfasi sui tumori e sulle malattie cardio-vascolari, infettive e psichiatriche; coinvolge ricercatori provenienti da Harvard, MIT e da diversi ospedali legati ad Harvard, che operano in discipline diverse, tra cui la medicina, la biologia, la chimica, l’informatica, la matematica e l’ingegneria.
Il gruppo di Data Science del Broad Institute è responsabile di FireCloud, una piattaforma aperta per l’analisi dei dati genomici che garantisce sicurezza ed elevate prestazioni; FireCloud consente l’accesso protetto a dati genomici presenti in TCGA (The Cancer Genome Atlas) e l’uso di GATK, un software sviluppato al Broad Institute per l’individuazione di mutazioni. Al termine di un percorso di integrazione del software, anche GMQL è disponibile su FireCloud. Usando una workspace pubblica creata per GMQL, i ricercatori possono vedere GMQL al lavoro su tre casi di studio di progressiva complessità, e possono quindi utilizzare il codice sviluppato al Politecnico di Milano per integrare e completare le loro analisi dei dati. Il gruppo del Politecnico ha fatto da apripista nella sperimentazione dell’uso delle workspace pubbliche, uno strumento di FireCloud per facilitare l’integrazione con strumenti software sviluppati da gruppi di ricerca esterni al Broad Institute.
Nel corso del progetto, il sistema sarà arricchito di strumenti per l’analisi dei dati e verrà reso sempre più efficiente, utilizzando vari framework per la gestione di dati disponibili su server paralleli e in ambiente cloud. Tra gli obiettivi del progetto vi è anche la costruzione di un open source messo a disposizione dei ricercatori biologici e clinici, che potranno usare servizi offerti dal sistema oppure scaricarlo e installarlo presso i loro centri. Mentre i servizi realizzati dal Politecnico di Milano useranno esclusivamente dati pubblici, messi a disposizione per uso secondario, cioè per attività di ricerca, l’installazione protetta del sistema in un contesto clinico potrà essere utilizzata per la cosiddetta “medicina personalizzata”, cioè l’adattamento delle terapie ai dati genomici di specifici pazienti. L’obiettivo più ambizioso di GeCo è la realizzazione di un Internet per la genomica, cioè di un modo di raccogliere dati genomici pubblicati da consorzi internazionali e dai ricercatori, e di un Google per la genomica, cioè un sistema di indicizzazione e ricerca su grandi raccolte di dati genomici pubblici. Questi strumenti potranno essere usati per facilitare in futuro lo studio approfondito di gravi malattie.
Cos’è la Genomica Computazionale
É la scienza che, partendo dal sequenziamento del genoma e grazie all’uso di analisi statistiche e computazionali, decifra la funzione delle regioni del genoma e costituisce pertanto il presupposto per le future scoperte nel campo della biologia e della medicina. Le tecniche di sequenziamento del genoma di nuova generazione NGS (Next Generation Sequencing) consentono oggi la produzione dell’intera sequenza del genoma umano a costi molto bassi. Parallelamente sono stati sviluppati algoritmi specializzati per estrarre le caratteristiche salienti del genoma che si vuole studiare, per evidenziare ad esempio le mutazioni o l’espressione dei geni, cioè la loro attività di trascrizione. La grande lacuna da colmare rimane però l’ideazione di un sistema capace di integrare i dati genomici estratti da tali algoritmi ottenendo un senso biologico interpretabile dai medici per comprendere meglio, ad esempio, lo sviluppo di gravi malattie o la loro dipendenza da fattori ambientali.
Testo redatto su fonti Politecnico di Milano del 12 maggio 2016 e del 21 giugno 2018
Per approfondimenti su GeCo: www.bioinformatics.deib.polimi.it/geco
Per approfondimenti su GMQL: www.bioinformatics.deib.polimi.it/genomic_computing
Image credit: Iliescu Catalin/123RF.COM
© Copyright ADEPRON – Riproduzione riservata
 SISTEMI INFORMATICI
SISTEMI INFORMATICI
Ricercatori CNR/MIT hanno sviluppato un algoritmo basato su un sistema matematico-informatico in grado di ridurre la congestione stradale anche senza viaggi condivisi
26.05.2018
Testo dell’articolo
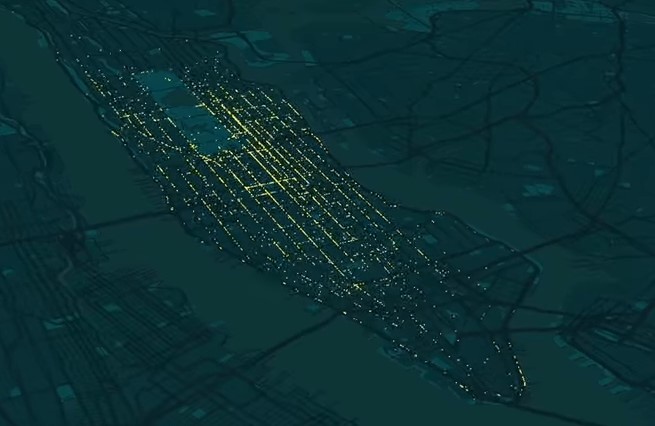
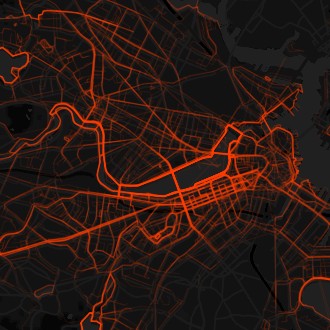
Un team di ricercatori dell’Istituto di Informatica e Telematica del Consiglio Nazionale delle Ricerche (CNR-IIT) di Pisa, del Massachusetts Institute of Technology (MIT) e della Cornell University di New York ha elaborato un sistema matematico-informatico in grado di ridurre del 30% le flotte di autoveicoli come quella dei taxi di New York, garantendo gli stessi livelli di servizio e senza ricorrere a viaggi condivisi, riducendo il traffico veicolare e favorendo anche turni di lavoro ridotti ai tassisti.
I ricercatori hanno utilizzato un metodo innovativo basato su un modello chiamato “rete di condivisione dei veicoli“. I membri del team hanno caratterizzato ogni viaggio in taxi in base a quattro parametri: tempo e coordinate GPS del punto di raccolta e di quello di discesa del passeggero. Un algoritmo ha quindi identificato la sequenza di viaggi che può essere servita da un singolo veicolo con il minimo tempo di percorrenza tra ciascun punto di raccolta e discesa. Il test ha coinvolto i 13.500 taxi di New York nel corso di un anno, per oltre 150 milioni di viaggi. L’applicazione del metodo dimostra che la flotta può essere ridotta di oltre il 30% rispetto ai livelli attuali, fornendo livelli di servizio ottimali per gli utenti.
I precedenti tentativi dei ricercatori di ridurre le flotte di veicoli potevano funzionare per piccole quantità e non per i grandi numeri di città come New York, Milano o Roma, mentre lo studio rivela che è possibile ridurre in maniera significativa anche flotte molto numerose. Questa riduzione potenziale del traffico non presuppone alcuna condivisione dei viaggi da parte dei passeggeri, ma è più semplicemente il frutto di una riorganizzazione che potrebbe essere eseguita con una semplice app per smartphone in tutto simile a quelle già in uso per prenotare taxi.
Le auto private lasceranno gradualmente il posto a servizi di mobilità condivisa con operatori che offriranno diverse modalità di trasporto su richiesta, così come l’avvento delle auto a guida autonoma e l’emergere di nuovi servizi di mobilità on-demand, cambieranno radicalmente il modo di viaggiare nelle città del futuro.
Testo redatto su fonte CNR del 24 maggio 2018
Per approfondimenti: Addressing the minimum fleet problem in on-demand urban mobility, DOI: 10.1038/s41586-018-0095-1 – Nature | 23.05.2018
Progetto Minimum Fleet: senseable.mit.edu/MinimumFleet
Images credit: Carlo Ratti/Senseable City Lab/MIT
© Copyright ADEPRON – Riproduzione riservata
 INTELLIGENZA ARTIFICIALE
INTELLIGENZA ARTIFICIALE
Un accordo di ricerca Italia-USA nel campo dei Big Data svilupperà un motore di intelligenza artificiale pensato specificamente per applicazioni IoT (Internet of Things)
15.03.2018
Testo dell’articolo
Enormi quantità di dati acquisiti in ambiti diversi saranno analizzati con tecniche sperimentali ed innovative attraverso algoritmi che si svilupperanno seguendo tre grandi filoni di ricerca: il primo filone riguardante i modelli statistici, i Data Analytics, che prevedono un processo di raccolta e analisi di grandi volumi di dati per estrarre informazioni nascoste e il Machine Learning, l’apprendimento automatico; il secondo riguarda invece la Feature Extraction e la Image Processing for Computer Vision, che lavora su funzioni di elaborazione di immagini e, in un secondo momento, permette al macchinario di prendere decisioni in base all’immagine elaborata; ed infine il terzo filone di ricerca riguarderà il Fog Computing e Opportunistic Networking, utili a distribuire senza soluzione di continuità risorse e servizi di calcolo, immagazzinamento di dati, controllo e funzionalità di rete sull’infrastruttura che connette il Cloud all’IoT.
La ricerca, della durata di 5 anni, offrirà un’opportunità unica di testare questi sistemi per una grande varietà di dispositivi, con milioni di unità già rilasciate in tutto il mondo.
I dati sono l’ingrediente fondamentale della trasformazione digitale. Le tecnologie più innovative nei prossimi anni, tra cui IoT, Intelligenza Artificiale, Blockchain, Machine Learning, sono tutte metodi di raccolta, analisi e archiviazione delle informazioni. Le opportunità aperte dall’uso dei dati e dalle metodologie oggi disponibili per il loro processamento offrono opportunità di migliorare e ottimizzare continuamente prodotti e servizi.
Testo redatto su fonte Politecnico di Torino del 13 marzo 2018
Images credit: Sergey Tarasov/Shutterstock.com
© Copyright ADEPRON – Riproduzione riservata
 COMPUTER SCIENCE
COMPUTER SCIENCE
“PASS 8”, il nuovo software che ricostruisce l’interazione dei fotoni gamma con i rivelatori del satellite Fermi della NASA, migliora le prestazioni del Large Area Telescope
10.01.2016
Testo dell’articolo
I dati relativi a ogni raggio gamma devono essere ricostruiti a partire dalle tracce che la coppia elettrone-positrone (risultato dell’interazione del raggio gamma con la materia del rivelatore) ha lasciato nel tracciatore. Passare dalle tracce delle particelle alla direzione d’arrivo e all’energia del fotone gamma è compito di un complesso software di ricostruzione che è parte integrante del telescopio Fermi. È un software pensato ben prima del lancio e che, pur funzionando egregiamente, con il tempo ha cominciato a mostrare qualche pecca. Con l’aumentare della statistica si è visto, infatti, che il programma di ricostruzione “perdeva” eventi alle energie più basse e a quelle più alte. Per risolvere il problema non era sufficiente intervenire in qualche parte del vecchio software, ma bisognava ripensare tutto dal principio.
È stato così deciso di sviluppare PASS 8, procedendo alla riscrittura totale del software di ricostruzione degli eventi gamma, un compito difficile che ha richiesto per circa quattro anni molto intensi lo sforzo di molti specialisti. PASS 8 ha notevolmente migliorato le prestazioni della missione Fermi, i cui dati sono stati tutti rianalizzati con il nuovo software. Nei laboratori dell’INFN sono stati integrati tutti i tracciatori al silicio del telescopio e concepiti molti degli algoritmi del nuovo software di ricostruzione, e a sette anni e mezzo dal lancio di Fermi, il LAT è ora uno strumento più potente. PASS 8 fa nascere una nuova sinergia tra l’astronomia gamma spaziale e quella ancorata a terra che sarà di grande beneficio per il mini Array di piccoli telescopi Cherenkov che INAF costruirà come precursore al Cherenkov Telescope Array.
I miglioramenti più importanti si registrano per le energie più basse (dove però la risoluzione angolare dello strumento è piuttosto scarsa) e a quelle più alte (dove invece la risoluzione angolare è al meglio). Per questo motivo i dati forniti da PASS 8 sono stati, inizialmente, usati per compilare un catalogo delle sorgenti rivelate da Fermi a energie tra 50 GeV e 2 TeV, un intervallo di energia che, fino ad ora, era stato appannaggio dei telescopi gamma a terra. Confrontando il nuovo catalogo Fermi con la compilazione delle sorgenti gamma viste da terra, utilizzando speciali telescopi che sfruttano l’effetto Cherenkov, si nota subito che Fermi vede più del doppio delle sorgenti rivelate dai telescopi gamma al suolo. L’aumento di sensibilità rende possibile rivelare sorgenti molto deboli, o abbassare notevolmente i limiti di flusso minimo rivelabile, come nel caso delle galassie nane, dove la mancata osservazione di fotoni gamma si traduce direttamente in un limite molto forte sulla massa e la probabilità di annichilazione delle particelle di materia oscura che domina questi sistemi.
Testo redatto su fonti ASI, INAF, INFN dell’8 gennaio 2016
Per approfondimenti:
Fermi Gamma-ray Space Telescope: fermi.gsfc.nasa.gov
Large Area Telescope (LAT): www-glast.stanford.edu
Image credit: NASA/Goddard Space Flight Center Conceptual Image Lab
© Copyright ADEPRON – Riproduzione riservata
 GRID E CLOUD COMPUTING
GRID E CLOUD COMPUTING
L’INFN coordinerà INDIGO-DataCloud, il progetto che con 11 milioni di euro realizzerà una nuova piattaforma software di tipo Cloud destinata alla ricerca scientifica europea
22.01.2015
Testo dell’articolo
Il mondo della ricerca europea lavora in realtà da molti anni alla costruzione di un’infrastruttura di calcolo distribuita e condivisa, la EGI (European Grid Infrastructure), che interconnette attraverso tecnologie di Grid Computing centinaia di centri di calcolo in tutta Europa e che è stata realizzata per immagazzinare, distribuire e analizzare, tra gli altri, i centinaia di milioni di GB di dati scientifici prodotti dal Large Hadron Collider (LHC) del CERN. La nuova iniziativa, che si basa però al modello del Cloud Computing, consentirà di effettuare un passo in avanti decisivo verso la realizzazione di una infrastruttura di calcolo a livello europeo più flessibile e in grado di meglio soddisfare le esigenze di un numero molto maggiore di diversi settori di ricerca. La costruzione della Grid in effetti aveva come obiettivo primario la condivisione delle risorse di calcolo, in vista di un compito estremamente complesso, come l’analisi dei dati di LHC.
Con questo progetto sarà realizzata una piattaforma software, completamente gratuita e open-source, che potrà operare su infrastrutture di rete sia pubbliche che private per rispondere allo stesso tempo alle esigenze di calcolo, elaborazione o archiviazione dati di ricercatori di discipline molto diverse, senza dover riscrivere ogni volta i software da zero, attraverso l’utilizzo di funzionalità comuni fornite dalla piattaforma stessa. Con INDIGO-DataCloud i ricercatori avranno quindi a disposizione uno strumento con cui accedere in modo semplice a risorse di calcolo e di archiviazione condivise e portare così a termine i calcoli e le elaborazioni più complesse, che non potrebbero svolgere con pochi computer o con il solo centro di calcolo del proprio laboratorio o ente.
Partecipano con grandi aspettative al progetto, ad esempio, gruppi di ricerca di punta in ambito biomedico, che studiano le strutture proteiche con applicazioni nella diagnosi di malattie o di sintesi di nuovi farmaci. La piattaforma INDIGO-DataCloud, inoltre, potrà essere molto utile anche per la gestione dei dati di grandi archivi di opere museali o di cataloghi bibliotecari. In futuro inoltre potrebbe consentire ai laboratori e centri di calcolo di integrare le proprie risorse con quelle di provider esterni, ottimizzando in tal modo l’utilizzo delle risorse e diminuendone i costi. In questi casi si porranno nuovi problemi di gestione della sicurezza e della privacy dei dati, per cui verranno sviluppate soluzioni ad hoc, vista l’importanza di queste problematiche per la ricerca fondamentale, rilevanza ancora maggiore in ambito biologico e medico.
Nell’ambito di Horizon 2020, l’INFN partecipa anche all’EGI-Engage (Engaging the Research Community towards an Open Science Commons), un altro grande progetto europeo che ha l’obiettivo di allargare e rafforzare l’infrastruttura di calcolo della ricerca europea attualmente esistente.
Testo redatto su fonte INFN del 21 gennaio 2015
Per approfondimenti sull’European Grid Infrastructure (EGI): www.egi.eu
Image credit: EGI
© Copyright ADEPRON – Riproduzione riservata
 SICUREZZA INFORMATICA
SICUREZZA INFORMATICA
PIDaaS, progetto europeo che metterà a disposizione dei cittadini un servizio sicuro di autenticazione su cellulare basato su nuove tecnologie di riconoscimento biometrico
15.11.2014
Testo dell’articolo
Questa tecnologia, nonostante ad oggi non sia ancora stata ampiamente adottata nel settore dei servizi di telefonia mobile, sebbene alcuni sistemi di autenticazione già la utilizzino, porterà vantaggi concreti sia per i cittadini sia per gli sviluppatori di applicazioni internet. Gli utenti finali avranno il controllo di chi e come possono essere usate le loro informazioni e i produttori di applicazioni web potranno integrare agevolmente l’autenticazione biometrica nei loro processi remoti di identificazione. Data la crescente necessità di garantire sicurezza nei servizi digitali per i cittadini, il progetto rappresenta una sfida tecnologica molto importante: i risultati saranno applicati e valutati in 3 ambiti chiave: e-commerce, servizi digitali per la salute e servizi ai cittadini più in generale.
Coordinato dal Consorzio CSI-Piemonte, il progetto PIDaaS, che avrà una durata di 30 mesi (luglio 2014 – dicembre 2016), è co-finanziato dal Competitiveness and Innovation Framework Programme (CIP) dell’Unione Europea e coinvolge 9 partner provenienti da 6 paesi: CSI-Piemonte (Italia), BANTEC (Spagna), Bdigital (Spagna), RICOH (Spagna), Fraunhofer IGD (Germania), Università di Kent (Regno Unito), e-Bros (Lituania), TicSalut (Spagna) e Gjøvik University College (Norvegia).
Testo redatto su fonte PIDaaS Consortium del 12 novembre 2014
Per approfondimenti: www.pidaas.eu
Image credit: Hong Kong Baptist University/Department of Computer Science
© Copyright ADEPRON – Riproduzione riservata
 DATABASE E BIG DATA
DATABASE E BIG DATA
Ricercatori della SISSA hanno proposto su “Science” una procedura efficiente per categorizzare e rappresentare in maniera sintetica enormi quantità di dati
27.06.2014
Testo dell’articolo
Gli insiemi di dati possono essere immaginati come una “nuvola” di punti in uno spazio a più dimensioni. Questi punti sono in genere dispersi in modi diversi: più rarefatti in una zona, più densi in un’altra. La CA serve a individuare in modo efficiente le zone più dense, raggruppando con questo criterio i dati in un certo numero di sottoinsiemi significativi. Ogni sottoinsieme corrisponde a una categoria.
“Pensate a un database di fotografie di volti”, spiega Alessandro Laio, professore di Fisica e Statistica Biologica della SISSA. “Nell’archivio ci possono essere più fotografie di una stessa persona, la CA serve a raggruppare tutti gli scatti relativi allo stesso individuo. Questo tipo di analisi viene fatto per esempio dai sistemi automatici di riconoscimento dei volti”. “Noi abbiamo cercato di ideare un algoritmo più efficiente di quelli attualmente usati, che risolva alcuni dei problemi classici della CA”, continua Laio. “Il nostro approccio si basa su un modo nuovo di individuare il centro dei cluster, cioè i sottoinsiemi” spiega Alex Rodrigez, autore insieme a Laio della ricerca.
“Provate a immaginare di dover individuare tutte le città del mondo, senza avere a disposizione una mappa. Un compito immane”, spiega Rodriguez. “Abbiamo perciò individuato un’euristica, cioè una regola semplice, una sorta di scorciatoia per ottenere il risultato”. Per scoprire se un luogo è una città infatti possiamo chiedere a ogni abitante di contare quanti “vicini” ha, ovvero quante persone vivono nel raggio di cento metri da casa sua. Una volta ottenuto questo numero, troviamo, per ogni abitante, la distanza minima a cui vive un altro abitante che ha più vicini di lui. “Questi due dati insieme”, spiega Laio, “ci dicono quanto densamente è abitata la zona in cui vive un individuo e quanto distanti sono fra loro i cittadini che vantano il numero maggiore di vicini. Incrociando in maniera automatizzata queste informazioni, per tutta la popolazione mondiale, troveremo gli individui che rappresentano i centri dei cluster, che corrispondono alle varie città”. “Il nostro algoritmo fa proprio questo tipo di calcolo, e può essere applicato in molti ambiti diversi”, aggiunge Rodriguez.
La performance della procedura si è rivelata ottimale: “abbiamo testato il nostro modello matematico sull’Olivetti Face Database, un archivio di ritratti fotografici, ottenendo risultati molto soddisfacenti. Il sistema riconosce correttamente la maggior parte degli individui, e non ha mai dato ‘falsi positivi’” commenta Rodriguez. “Questo significa che in qualche caso non ha riconosciuto un soggetto, ma non ha mai confuso un individuo con un altro. Rispetto ad altri metodi simili il nostro si è rivelato particolarmente efficace nell’eliminare gli outlier, cioè quei punti molto diversi dagli altri che tendono a sballare l’analisi”.
Testo redatto su fonte SISSA del 27 giugno 2014
Per approfondimenti: Clustering by fast search and find of density peaks, DOI: 10.1126/science.1242072 – Science | 27.06.2014
Image credit: SISSA
© Copyright ADEPRON – Riproduzione riservata
 INFRASTRUTTURE DIGITALI
INFRASTRUTTURE DIGITALI
“Ofelia”, l’infrastruttura che agevolerà la nascita di internet del futuro e contribuirà allo sviluppo di servizi “cloud” sicuri, affidabili e immuni perfino ai black out
12.11.2013
Testo dell’articolo
“Per sviluppare internet del futuro – spiega Piero Castoldi, docente coordinatore dell’Unità di ricerca ‘Telecomunicazioni’ all’Istituto TeCIP, nell’annunciare la nascita di ‘Ofelia’ – la programmabilità delle reti è ritenuta cruciale per fronteggiarne la complessità crescente e l’impatto dei relativi costi di gestione, dal momento che qualsiasi aspetto della connettività può essere controllato da un programma software. É come se potessimo regolare il traffico lungo le strade di una città usando un diffuso e capillare impianto semaforico, per decidere l’accesso alle singole strade, i sensi di percorrenza, il numero di corsie per ciascun senso di percorrenza. Potremmo allora scrivere programmi software che, in base al traffico del momento oppure a seconda dei giorni della settimana, adattino la capacità delle strade – continua Piero Castoldi – per evitare congestioni o per creare corsie preferenziali. Nelle reti programmabili, in maniera analoga, con un programma si può decidere il modo con cui i pacchetti di dati viaggiano nella rete ed è possibile cambiarne le rotte a seconda delle esigenze, ad esempio predisponendo una connessione più veloce a favore di un trasferimento dati video verso un certo utente, liberandosi al tempo stesso da sofisticate e rigide configurazioni dei dispositivi fisici di trasmissione”.
L’infrastruttura “Ofelia” è il risultato di un progetto finanziato dall’Unione Europea per quasi quattro milioni e mezzo di euro, con il coinvolgimento di una federazione di industrie leader come Deutsche Telekom, Nec, Adva Optical e di istituzioni accademiche fra le quali la Standford University. L’infrastruttura si compone di dieci punti operativi, incluso quello di Pisa, installati presso gli enti coinvolti nella sperimentazione e interconnessi per offrire una variegata gamma di tecnologie di rete e di servizi, come la trasmissione ad alta velocità su rete ottica, l’instradamento di dati di tipo cognitivo (basati su qualunque caratteristica del pacchetto dati, non solamente l’indirizzo di destinazione) e servizi di virtualizzazione (la possibilità di utilizzare porzioni di una risorsa fisica per scopi diversi). Il CNIT e l’Istituto TeCIP della Scuola Superiore Sant’Anna di Pisa hanno contribuito nel campo delle reti programmabili grazie ai “data center” che costituiscono i computer della rete internet, ovvero la spina dorsale dell’infrastruttura per fornire servizi di “cloud computing”. Quest’ultimo può essere considerato la maggiore evoluzione tecnologica offerta dalla rete permettendo – di solito sotto forma di un servizio offerto “on-demand” da un provider – di archiviare e di elaborare dati grazie all’utilizzo di risorse hardware e software (server, dischi, applicazioni) distribuite nei “data center” e offerte in maniera virtuale attraverso internet. Le reti programmabili, che possono essere sperimentate attraverso “Ofelia”, giocano un ruolo chiave anche nella fornitura di servizi “cloud”. I servizi di rete tra i “data center” o verso l’utente possono essere configurati in maniera dinamica sulla base del servizio. Il CNIT contribuisce con studi e con sperimentazione sul “network as a service” ovvero sui servizi di connettività virtualizzati e attivati su richiesta dell’utente, per rendere più efficiente, più fluida e più affidabile la fornitura di servizi “cloud”, con benefici in termini di qualità del servizio reso all’utente.
Barbara Martini, ricercatrice del CNIT e coordinatrice operativa del progetto “Ofelia”, anticipa l’impatto dei risultati: “Il ruolo della rete guadagna sempre più importanza per il crescente volume di traffico e dalla sua variabilità a causa dell’impiego sempre più intenso di applicazioni ‘cloud’, ma soprattutto per il fatto che sempre più attività commerciali faranno affidamento su questi servizi. Da una recente indagine emerge che la rete e la sua adeguatezza sono viste come la principale sfida per l’utilizzo su larga scala di questi servizi. Infatti, la principale preoccupazione degli utenti, specialmente di quelli ‘business’, è la disponibilità effettiva e la affidabilità delle applicazioni tramite il ‘cloud’, come il recente impatto del black out del motore di ricerca usato dalla maggior parte dei navigatori mondiali e dei relativi servizi ha dimostrato di recente. Ne consegue – conclude – che rendere Internet adeguata ai servizi ‘cloud’ rappresenta un valore aggiunto sul quale cui molti operatori di rete stanno intravedendo nuove opportunità di sviluppo e di guadagno”.
Testo redatto su fonte Scuola Superiore Sant’Anna di Pisa del 12 novembre 2013
© Copyright ADEPRON – Riproduzione riservata
 SERVER E DATA CENTER
SERVER E DATA CENTER
ENI inaugura il Green Data Center, primo al mondo per efficienza energetica: ospiterà tutti i sistemi IT dell’ENI, ottimizzando i costi e riducendo le emissioni di CO2
29.10.1013
Testo dell’articolo
“Diamo all’energia un’energia nuova” è il significato della decisione di mettere il progetto a disposizione delle università e dei centri di ricerca – un modello aperto per far si che l’investimento di ENI possa essere prototipo d’eccellenza, innovativo e sostenibile.
Il nuovo centro sarà tra i primi in Europa per tipologia e dimensione (5.200 mq utili, fino a 30 MW di potenza IT, concentrazione di potenza elettrica fino a 50 kW/mq) e primo al mondo per efficienza energetica.
Sono impiegate le più innovative infrastrutture per il risparmio energetico, abbattendo l’emissione di CO2 di 335 mila tonnellate annue (circa l’1% dell’obiettivo italiano di Kyoto per l’energia), e riducendo notevolmente i costi operativi. É stato raggiunto il record mondiale in termini di efficienza energetica per i mega-center, misurato come il rapporto tra l’energia totale utilizzata e l’energia dedicata all’informatica: per il Green Data Center questo rapporto sarà al di sotto del valore di 1,2, miglior risultato a livello mondiale. La media italiana presenta ancora valori tra 2 e 3.
L’efficienza del Green Data Center deriva soprattutto dal particolare sistema di raffreddamento che, con i suoi 6 camini, caratterizza anche la skyline dell’impianto. Per raffreddare gli apparati informatici, i Data Center tradizionali utilizzano ininterrottamente sistemi di condizionamento e ventilazione forzata. Il Green Data Center ENI, invece, ha un sistema che regola la temperatura usufruendo, per almeno il 75% del tempo, direttamente dell’aria esterna. Questa tecnica limita quindi l’utilizzo di condizionatori a meno del 25% del tempo.
Un risultato ancor più d’eccellenza se si considera che l’impianto è collocato a livello del 45° parallelo, mentre i Data Center con caratteristiche simili sorgono generalmente a nord e in ambienti più freddi (come per esempio le Montagne Rocciose negli Stati Uniti). Il sistema di “free-cooling” restituisce anche aria più pulita agli ambienti esterni. Infatti, prima di arrivare ai computer, l’aria viene filtrata dalle polveri, eliminando circa 3.000 chilogrammi all’anno.
L’impianto è costruito nell’immediata prossimità della centrale Enipower di Ferrera Erbognone, che meglio risponde ai requisiti per l’alimentazione elettrica del Data Center: la potenza richiesta è già disponibile e la produzione di energia avviene mediante turbogas a metano, utilizzando la più pulita tra le fonti fossili.
Grazie allo stimolo innovativo derivante dal progetto Green Data Center, i partner tecnologici hanno messo a punto soluzioni totalmente innovative: ad esempio sul fronte elettrico, sono stati sviluppati e certificati gruppi di continuità (UPS) capaci di intervenire quando necessario con la massima efficienza.
Testo redatto su fonte ENI del 29 ottobre 2013
© Copyright ADEPRON – Riproduzione riservata
 INFRASTRUTTURE DIGITALI
INFRASTRUTTURE DIGITALI
GARR-X Progress, il progetto che integra una rete ultra veloce con servizi di calcolo e storage distribuito per la ricerca, l’istruzione e la competitività nel Sud
14.10.2013
Testo dell’articolo
Sono centinaia le sedi coinvolte tra università, centri di ricerca, istituti culturali, ospedali a carattere scientifico che beneficeranno di capacità di accesso alla rete fino a 10 Gbps, portando la capacità aggregata ad oltre 400 Gbps, ovvero più di 4 volte il valore attuale. La fibra ottica arriverà anche nelle scuole: saranno circa 400 gli istituti scolastici nei capoluoghi di provincia ad essere connessi a 100 Mbps. Si tratta di un primo passo per estendere le potenzialità della rete GARR, interconnessa a livello mondiale, anche al mondo dell’istruzione, per favorire una didattica di qualità rafforzando il legame tra scuola, università e ricerca. GARR-X Progress non è solo connettività, bensì un ambizioso progetto per colmare l’attuale lacuna di infrastrutture digitali proiettando le regioni interessate in una posizione di prima fila nella competizione globale, grazie alla possibilità di accedere ad altissima capacità a risorse di calcolo e storage distribuito utilizzate per la gestione di Big Data e l’erogazione di servizi Cloud.
“L’obiettivo che ci poniamo è di fornire un valido supporto alla ricerca di eccellenza per favorire la partecipazione nei programmi nazionali ed europei anche in vista di Horizon 2020”, ha dichiarato Claudia Battista, coordinatore del progetto. “La disponibilità di un ambiente collaborativo fatto di collegamenti simmetrici e accesso semplice e sicuro a risorse ICT per gestire grandi quantità di dati, aiuterà la partecipazione attiva nell’ambito dello Spazio Europeo della Ricerca e crediamo possa dare un forte impulso per attrarre talenti, conoscenze e competenze nelle regioni del Sud”. In linea con gli obiettivi delle agende digitali, sia italiana che europea, GARR-X Progress si propone di diventare il fattore abilitante di collaborazioni esistenti o ancora da inventare e nello stesso tempo, permetterà di sperimentare in un ambiente reale modelli innovativi di infrastrutture digitali da estendere a tutto il territorio nazionale.
Tra gli obiettivi del progetto c’è anche quello di promuovere la crescita e lo sviluppo di imprenditorialità innovativa sul territorio attraverso l’accesso a servizi e infrastrutture digitali avanzate e la creazione di competenze. Nell’ottica di favorire la diffusione della banda ultralarga nel Mezzogiorno e l’aumento della competitività nel settore ICT, verranno creati nuovi Punti di Interscambio neutrali di traffico tra operatori e fornitori di servizio (NAP). Il finanziamento di 46,5 milioni di euro complessivi per l’intero progetto prevede anche dei percorsi di formazione sull’uso, la valorizzazione e lo sviluppo delle infrastrutture digitali rivolti a diverse tipologie di destinatari. L’offerta formativa comprende due master universitari per laureati, dottori di ricerca o giovani ricercatori; corsi di formazione a distanza per il personale direttivo degli enti coinvolti; moduli di aggiornamento professionale in autoapprendimento.
Testo redatto su fonte GARR-X Progress del 14 ottobre 2013
Per approfondimenti: www.garrxprogress.it
© Copyright ADEPRON – Riproduzione riservata













